All the fonts from CU Writer
CU Writer, a public domain word processor from 1989–1993, contains 55 bitmap fonts, which has now been extracted. They can be useful when displaying Thai text on a low-resolution screen or a low-DPI printer.

The source code and all the files can be found on GitHub.
GitHub Repositoryhttps://github.com/dtinth/cu-writer-fonts
How it started
It was a weird rabbit hole. I stumbled upon a PDF file of a book printed in 1994. It seems to feature a monospaced Thai typeface that I couldn’t find anywhere in modern times, yet it looks much better than all the modern monospaced Thai fonts I see nowadays.

However, the stretched text reminds me of an old word processor called CU Writer, a freeware developed by Chulalongkorn University.
I have never used it; only saw its screenshot. Nevertheless, its stretched text kinda made an impression.

…but its on-screen font doesn’t look like the one in the book at all. But whatever. I like obscure fonts, so I thought I would forget about the book for now, and try to extract all the fonts from CU Writer, and see what’s inside.
I’m also interested in bitmap fonts because I use a low-DPI label printer, and bitmap fonts looks much better on it.
Inside CU Writer 1.6
The software package contains many font files in various file formats. 39 files, to be exact.
| .FON | .PRN | .P24 | .FNT |
|---|---|---|---|
| NORMAL.FON | NORMAL.PRN | NORMAL.P24 | CU_HP_10.FNT |
| NORMAL2.FON | NORMAL2.PRN | NORMAL2.P24 | CU_HP_12.FNT |
| NORMAL3.FON | NORMAL3.PRN | NORMAL3.P24 | |
| NORMAL4.FON | NORMAL4.PRN | NORMAL4.P24 | |
| NORMALS.PRN | NORMALS.P24 | ||
| NORMALS2.PRN | NORMALS2.P24 | ||
| NORMALS3.PRN | NORMALS3.P24 | ||
| NORMALS4.PRN | NORMALS4.P24 | ||
| ITALIC.FON | ITALIC.PRN | ITALIC.P24 | |
| ITALIC2.FON | ITALIC2.PRN | ITALIC2.P24 | |
| ITALIC3.FON | ITALIC3.PRN | ITALIC3.P24 | |
| ITALIC4.FON | ITALIC4.PRN | ITALIC4.P24 | |
| ITALICS.PRN | ITALICS.P24 | ||
| ITALICS2.P24 | |||
| ITALICS3.P24 | |||
| ITALICS4.P24 |
I could not find any information about these files. But thankfully, the source code for CU Writer v1.41 is publicly available. Unfortunately though, it contains less font and does not contain the .FNT files or the code to load them at all. So let’s start with what we have.
The FON, PRN, and P24 files
I asked Claude to help me with understanding the format.
I used Continue.dev and fed the model with the source code.
Since I’m interested in the higher-quality printer fonts, I decided to focus on the .p24 files. So I dive in:
The information wasn’t entirely accurate. For example, all the bits are actually used. The 3 bytes represent 24 pixels from top to bottom, i.e. every 3 bytes represents a vertical slice of the bitmap. It took a bit of tinkering in Ruby to figure this out:
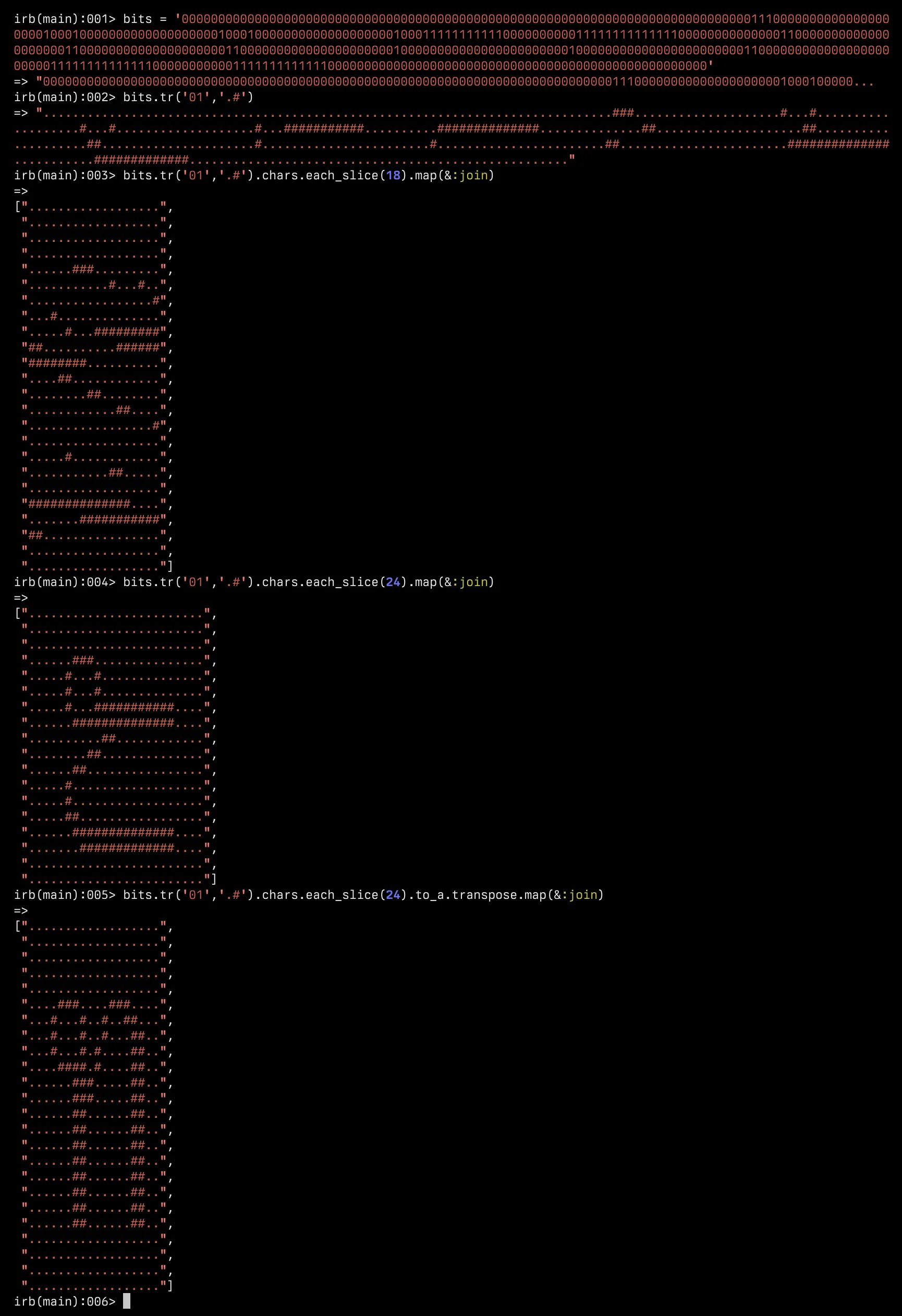
From the source code, each of these file types has its own loading function. Thankfully, they are all similar. The .fon, .prn, and .p24 files contains just the bitmap data, and characters data is arranged sequentially. This makes it pretty easy to parse.
| File type | FON | PRN | P24 |
|---|---|---|---|
| Number of glyphs | 256 | 224 | |
| Orientation | Left-to-right, top-to-bottom | Top-to-bottom, left-to-right | |
The FNT files
Now, the .fnt files are different. These files are much larger than all the other files, and there are only two of them: CU_HP_10.FNT and CU_HP_12.FNT. Unfortunately, the source code does not contain any information about these files, so I had to make some (correct) guesses:
These files are likely used for high-quality printing due to the “HP” in their names. This matches with this description from Wikipedia, which describes that it works with 10 and 12 characters per inch printers by HP LaserJet.
CUPRINT รุ่น 1.41 เดือนกรกฎาคม พ.ศ. 2534 ซึ่งสามารถพิมพ์ข้อความขนาด 10 และ 12 ตัวอักษรต่อนิ้ว และใช้กับเครื่องพิมพ์เอชพี เลเซอร์เจ็ท …
They probably contain multiple fonts, as they are much larger than the other files and there are only two of them.
With these assumption, let’s ask Claude for help with pattern recognition:
The information wasn’t entirely accurate1, but was enough for me to continue my exploration. I used ImHex to view the binary data and, after some time, was able to decode it. I won’t go into the details (you can check out hp.ts for that), but it contains a repeating patterns throughout the file.
Pattern description
Convention:
- Hexadecimal numbers represent raw bytes.
- N represents a number encoded in ASCII. For example, the number 24 is encoded as hex
32 34. - Quoted strings represent ASCII-encoded text.
Pattern:
1B "*c" N "D"- This seems to denote the start of the Nth font. For example
1B "*c0D"means font number 0.
- This seems to denote the start of the Nth font. For example
1B ")s" N "W"followed by N bytes of payload- The payload seems to contains information about the font, including the font name. I haven’t looked into it.
1B "*c" N "E"- This seems to denote the character number N. For example
1B "*c33E"means character number 33.
- This seems to denote the character number N. For example
1B "(s" N "W"followed by N bytes of payload- This is the character data.
- The payload contains:
- 16 bytes of header in binary. I haven’t looked into it yet, but the
payload[13]contains the width of the bitmap data. - The rest of the data is the bitmap data of the character, 1 bit per pixel.
- 16 bytes of header in binary. I haven’t looked into it yet, but the
With that, I converted all the fonts into JSON files. Then I created an HTML page that loads these JSON file and turns them into a bitmap font. All the code is in the GitHub repo, so you can check it out:
GitHub Repositoryhttps://github.com/dtinth/cu-writer-fonts
By the way, if you are interested in old-school PC fonts, while researching I also stumbled upon The Oldschool PC Font Resource which has tons of old fonts.
Found it
Indeed, the book mentioned at the beginning seems to use one of the fonts from CU Writer.
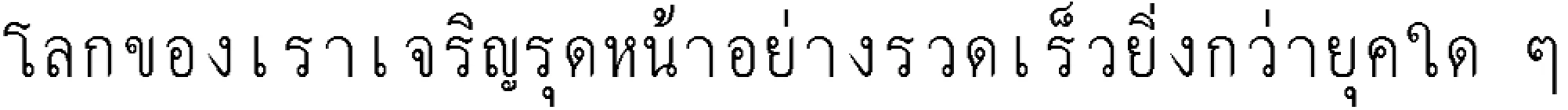
Footnotes
For example, there is no file header (but font headers exist), and there is no run-length encoding used. ↩